软件版本
- Spring Boot : 2.2.1.RELEASE
- Spring Data Elasticsearch : 3.2.1.RELEASE
- Elasticsearch : 6.8.4
- Elasticsearch IK 分词器 : 6.8.4
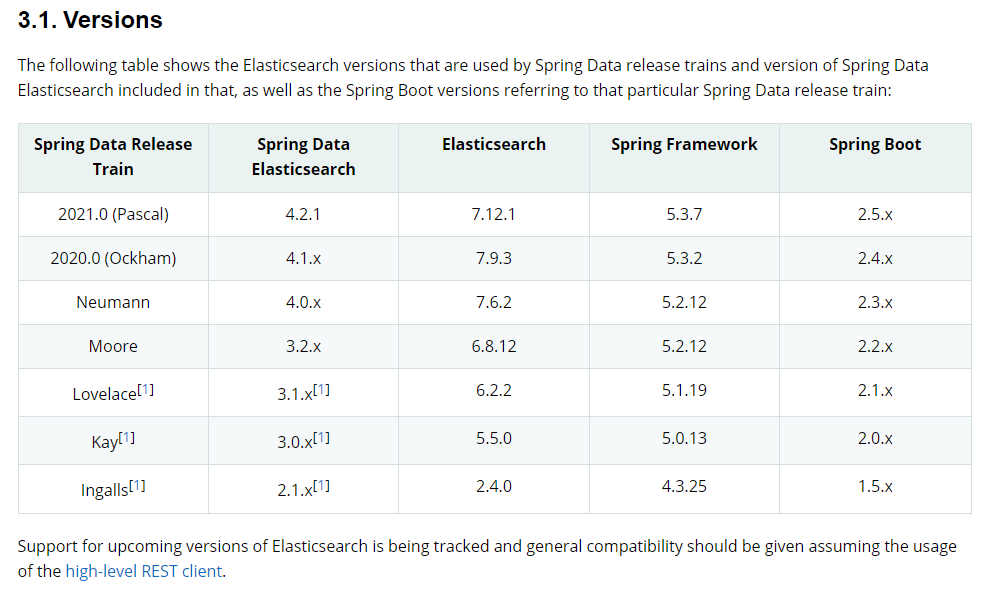
软件版本应当尽量保持较高的一致性,比如 IK 分词器必须跟 Elasticsearch 的版本号一样,否则 Elasticsearch 服务会启动失败。
Spring 的文档有版本兼容表格:https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/#preface.versions
整合过程
项目 pom 文件添加 maven 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>项目 yml 文件添加 elasticsearch 服务地址
elasticsearch:
rest:
# 逗号分隔的Elasticsearch实例使用的列表
uris: http://localhost:9200
# 链接超时时间
connection-timeout:
# 读取超时时间
read-timeout:
# ES 用户名
username:
# ES 密码
password:创建 ElasticsearchRepository 的子类
创建一个继承 Spring Data ElasticsearchRepository 的子类,该子类可直接拿来进行增删改查的操作
public interface WPPostEsRepository extends ElasticsearchRepository<WPPost, String> {
Page<WPPost> findByTitleOrContent(String title, String content, Pageable pageable);
}实体类增加注解
@Document(indexName = "wordpress", type = "post")
public class WPPost implements java.io.Serializable{
@Id
private Integer id;
private Integer parentId;
@Field(type = FieldType.Text, analyzer = "ik_max_word",searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String categoryNames;
构建索引
public void rebuildIndex() throws Exception{
elasticsearchRestTemplate.deleteIndex(WPPost.class);
elasticsearchRestTemplate.createIndex(WPPost.class);
WPPostRequest wpPostRequest = new WPPostRequest();
wpPostRequest.setFindAll(true);
PaginationResponse<WPPost> paginationResponse = findByPage(wpPostRequest);
wpPostEsRepository.saveAll(paginationResponse.getList());
}采用 saveAll 方法,批量构建索引,提高构建速度
查询索引
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.withPageable(PageRequest.of(wpPostRequest.getPage() - 1, wpPostRequest.getPageSize()));
if(StringUtils.isNotBlank(wpPostRequest.getKeyword())){
// queryBuilder.withQuery(QueryBuilders.queryStringQuery(wpPostRequest.getKeyword()));
queryBuilder.withQuery(QueryBuilders.multiMatchQuery(wpPostRequest.getKeyword(),"title","content","categoryNames"));
}
SearchQuery searchQuery = queryBuilder.build();
// Page<WPPost> esPageResult = elasticsearchRestTemplate.queryForPage(searchQuery, WPPost.class);
Page<WPPost> esPageResult = wpPostEsRepository.search(searchQuery);
return new PaginationResponseBuilder() {
@Override
public int count() {
Long cnt = esPageResult.getTotalElements();
return cnt.intValue();
}
@Override
public List find() {
List<WPPost> list = esPageResult.toList();
if(CollectionUtils.isEmpty(list)){
return list;
}
return list;
}
}.handlePaginationRequest(wpPostRequest);使用 multiMatchQuery 查询多个字段,包括文章标题、正文、分类,查询文章分类可以提高关键词搜索命中率。
ik_max_word 和 ik_smart 的区别
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
两种分词器使用的最佳实践是:索引时用ik_max_word,在搜索时用ik_smart。
即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。