Java 中的 HashMap 是一种散列表。
散列表
散列表(Hash table,也叫哈希表)是一种基于数组的数据结构,可以用来存储键值对(key-value pair)。散列表使用散列函数对 key 进行计算得到 hash,再对 hash 进行取余运算得到 value 在数组中的索引。
散列表通过计算得到数据在内存中的存储位置,提高了查找数据的效率。举一个通俗的例子,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表,在表中根据首字母查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则,存放首字母的表对应散列表。
散列函数特性
- 如果两个散列值不相同,那么这两个散列值的原始输入值也是不相同的。
- 如果两个散列值相同,那么这两个散列值的原始输入值不一定相同,如果原始输入值相同,那么这种现象称为冲突。
常用散列函数
- 直接定址法:直接以关键字k或者k加上某个常数(k+c)作为哈希地址。
- 数字分析法:提取关键字中取值比较均匀的数字作为哈希地址。
- 除留余数法:用关键字k除以某个不大于哈希表长度m的数p,将所得余数作为哈希表地址。
- 分段叠加法:按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。
- 平方取中法:如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址。
- 伪随机数法:采用一个伪随机数当作哈希函数。
处理冲突方法
- 开放定址法:开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
- 链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
- 再哈希法:当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。
- 建立公共溢出区:将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
HashMap 的数据结构
在 Java 中,保存数据有两种比较简单的数据结构:数组和链表。
数组的特点:
- 创建时需要指定容量大小,所有元素需要连续存储,扩容麻烦。
- 插入元素麻烦,需要把其它元素往后移动来腾出位置。
- 删除数据麻烦,需要把其它元素往前移动来保持连续。
- 支持随机读取,只要知道元素的索引,就可以直接读取。
链表的特点:
- 创建时不需要指定容量大小,所有元素不需要连续存储,扩容方便。
- 插入数据方便,只需要修改元素之间的引用,不需要移动其它元素。
- 删除数据方便,只需要修改元素之间的引用,不需要移动其它元素。
- 不支持随机读取,访问某个位置的元素要从第一个元素开始遍历。
上面我们提到过,常用的散列函数冲突解决办法中有一种方法叫做链地址法,这个方法其实就是将数组和链表组合在一起,共同发挥两者的优势,HashMap 用的就是链地址法。
HashMap 添加数据时通过 hash 函数计算得出 key 的 hash 值,再根据 hash 值计算得出数据在数组中的存放位置。如果不同的 key 计算得出的 hash 值是相同的,那就说明有 hash 冲突。发生了 hash 冲突就在原有的链表后面追加新数据,也就是说根据 hash 值和 key 唯一确定数据的真实位置。
HashMap 源码分析
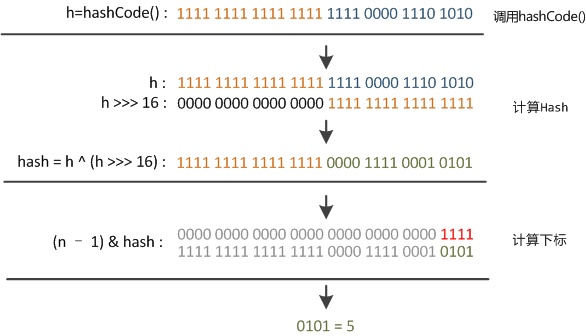
这是 Java 8 中 HashMap 的 hash 方法源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这个 hash 方法计算得出的散列值是一个 int 型,32 位 int 类型取值范围是 -2147483648 到 2147483647,如果直接把散列值拿来作为数组下标的话,会出现HashMap 的数组放不下的情况,毕竟 HashMap 扩容之前的数组初始大小也只有 16。所以这个散列值是不能直接拿来用的,用之前还要先对数组的长度做取余运算,得到的余数才能用来作为数组下标。取余运算举例:
14%16 = 14 存放在14下标位
18%16 = 2 存放在2下标位
32%16 = 0 存放在0下标位以下是 java 7 中 HashMap 取余运算相关的源码,虽然 java 8 没有这个 indexFor 方法,但原理是一样的,java 8 只是没有把取余运算的代码单独放到一个方法内而已:
bucketIndex = indexFor(hash, table.length);
static int indexFor(int h, int length) {
return h & (length-1);
}可以看到用按位与运算去模拟取余运算,按位与运算的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15,2进制表示是00000000 00000000 00001111,和某散列值做按位与运算如下,结果就是截取了最低的四位值。

按位与运算效率比取余运算高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制。这个技巧的原理是:
公式:X % 2^n = X & (2^n – 1)
其中 2^n表示2的n次方,也就是说,一个数对 2^n 取余等于一个数和 (2^n – 1)做按位与运算 。
假设 n 为 3,则 2^3 = 8,表示成 2 进制就是 1000。2^3 -1 = 7 ,即 0111。
此时 X & (2^3 – 1) 就相当于取 X 的 2 进制的最后三位数。
从 2 进制角度来看,X / 8相当于 X >> 3,即把 X 右移 3 位,此时得到了 X / 8 的商,而被移掉的部分(后三位),则是 X % 8,也就是余数。
根据以上的原理分析,HashMap 使用的数组长度要取 2 的整次幂,而 HashMap 扩容之前的数组初始大小也确实是 2 的倍数,初始值是 16,之后每次扩充为原来的 2 倍。
位运算相比取余运算提升了性能,但无论是用取余运算还是位运算都无法直接解决 hash 冲突较大的问题,因此还需要对生成的 hashCode 再做一些加工。
再来看下 hash 方法的源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这段代码对 key 的 hashCode 进行扰动计算,防止不同 hashCode 的高位不同但低位相同导致的 hash 冲突。通过把高位的特征和低位的特征组合起来,降低了哈希冲突的概率。
有人做过统计,当 HashMap 数组长度为 512 的时候,在没有扰动函数的情况下,发生了 103 次碰撞,接近 30%。而在使用了扰动函数之后只有 92 次碰撞,碰撞减少了将近 10%,看来扰动函数确实还是有功效的。 Java 7 的 hash 方法做了 4 次扰动,但其实扰动做 1 次就够了,次数多了的话会出现边际效用递减,所以 Java 8 就改成 1 次了。
在 Java 8 之前,HashMap 是通过链地址法解决冲突,使用单向链表来存储相同索引值的元素。在最坏的情况下,这种方式会将 HashMap 的 get 方法的性能从 O(1) 降低到 O(n)。为了解决在频繁冲突时性能降低的问题,Java 8 使用红黑树来替代单向链表存储冲突的元素,将最坏情况下的性能从 O(n) 提高到 O(logn)。
HashMap 时间复杂度
HashMap put/get 方法的时间复杂度不是固定不变的,可能的时间复杂度有O(1)、O(logn)、O(n),以 put 方法为例:
第一步:key.hashcode(),时间复杂度O(1)。
第二步:判断链表里是否有元素,如果没有就 new 一个 entry 节点插入到数组中,时间复杂度O(1)。
第三步:如果链表里有元素,并且元素个数小于 6,则调用 equals 方法,比较是否存在相同名字的 key,不存在则 new一个 entry 插入到链表尾部,时间复杂度O(1)+O(n)=O(n)。
第四步:如果链表里有元素,并且元素个数大于 6,则调用 equals 方法,比较是否存在相同名字的 key,不存在则 new 一个 entry 插入到链表尾部,时间复杂度O(1)+O(logn)=O(logn),红黑树查询的时间复杂度是logn。